
11 Inference for Regression
11.1 Refresher: Professor evaluations data
Let’s revisit the professor evaluations data that we analyzed using multiple regression with one numerical and one categorical predictor. In particular
- \(y\): outcome variable of instructor evaluation
score - predictor variables
- \(x_1\): numerical explanatory/predictor variable of
age - \(x_2\): categorical explanatory/predictor variable of
gender
- \(x_1\): numerical explanatory/predictor variable of
library(ggplot2)
library(dplyr)
library(moderndive)
load(url("http://www.openintro.org/stat/data/evals.RData"))
evals <- evals %>%
select(score, ethnicity, gender, language, age, bty_avg, rank)First, recall that we had two competing potential models to explain professors’ teaching scores:
- Model 1: No interaction term. i.e. both male and female profs have the same slope describing the associated effect of age on teaching score
- Model 2: Includes an interaction term. i.e. we allow for male and female profs to have different slopes describing the associated effect of age on teaching score
11.1.1 Refresher: Visualizations
Recall the plots we made for both these models:
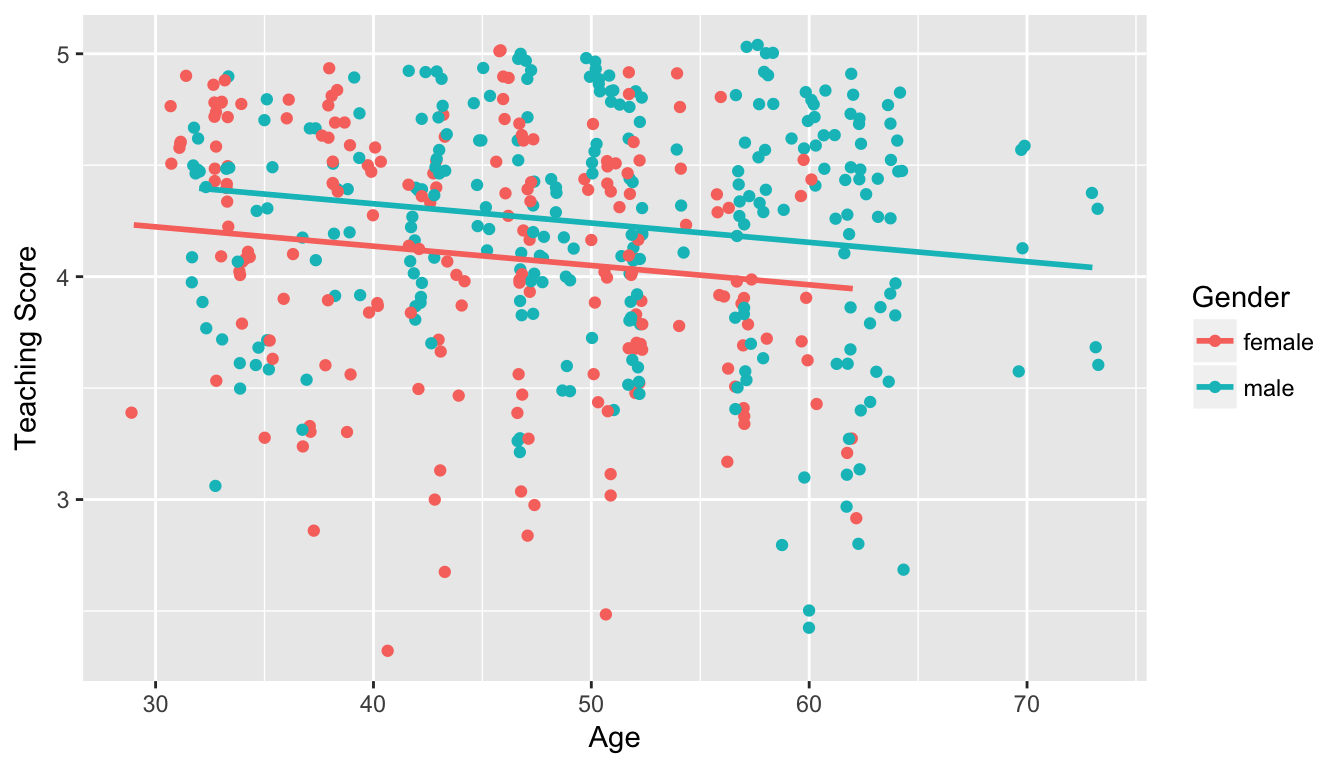
Figure 11.1: Model 1: no interaction effect included
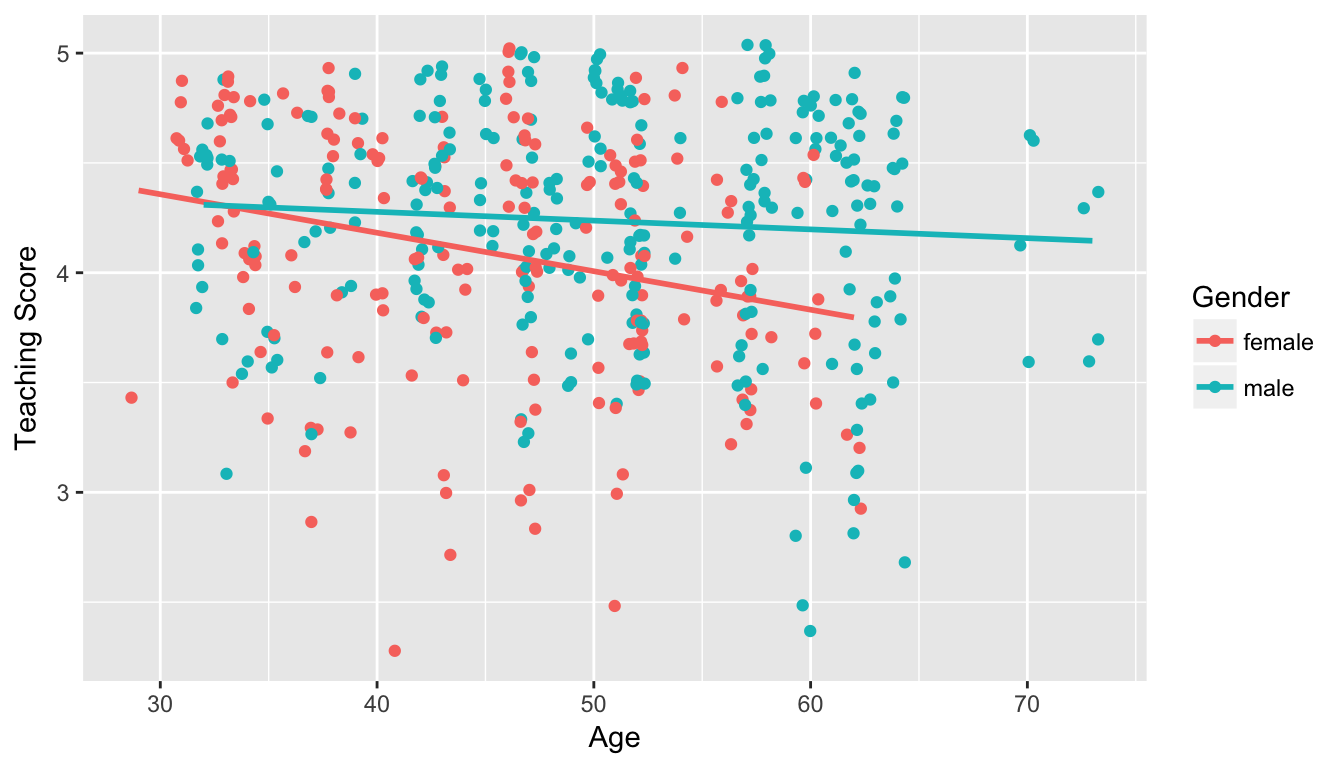
Figure 11.2: Model 2: interaction effect included
11.1.2 Refresher: Regression tables
Last, let’s recall the regressions we fit. First, the regression with no interaction effect: note the use of + in the formula.
score_model_2 <- lm(score ~ age + gender, data = evals)
get_regression_table(score_model_2)| term | estimate | std_error | statistic | p_value | conf_low | conf_high |
|---|---|---|---|---|---|---|
| intercept | 4.484 | 0.125 | 35.79 | 0.000 | 4.238 | 4.730 |
| age | -0.009 | 0.003 | -3.28 | 0.001 | -0.014 | -0.003 |
| gendermale | 0.191 | 0.052 | 3.63 | 0.000 | 0.087 | 0.294 |
Second, the regression with an interaction effect: note the use of * in the formula.
score_model_3 <- lm(score ~ age * gender, data = evals)
get_regression_table(score_model_3)| term | estimate | std_error | statistic | p_value | conf_low | conf_high |
|---|---|---|---|---|---|---|
| intercept | 4.883 | 0.205 | 23.80 | 0.000 | 4.480 | 5.286 |
| age | -0.018 | 0.004 | -3.92 | 0.000 | -0.026 | -0.009 |
| gendermale | -0.446 | 0.265 | -1.68 | 0.094 | -0.968 | 0.076 |
| age:gendermale | 0.014 | 0.006 | 2.45 | 0.015 | 0.003 | 0.024 |
11.1.3 Refresher: Residual analysis
Let’s compute the residuals using augment() to see if there is a pattern.
regression_points <- get_regression_points(score_model_3)
regression_points# A tibble: 463 x 6
ID score age gender score_hat residual
<int> <dbl> <dbl> <fct> <dbl> <dbl>
1 1 4.70 36.0 female 4.25 0.448
2 2 4.10 36.0 female 4.25 -0.152
3 3 3.90 36.0 female 4.25 -0.352
4 4 4.80 36.0 female 4.25 0.548
5 5 4.60 59.0 male 4.20 0.399
6 6 4.30 59.0 male 4.20 0.0990
7 7 2.80 59.0 male 4.20 -1.40
8 8 4.10 51.0 male 4.23 -0.133
9 9 3.40 51.0 male 4.23 -0.833
10 10 4.50 40.0 female 4.18 0.318
# ... with 453 more rowsFirst the histogram:
ggplot(regression_points, aes(x = residual)) +
geom_histogram(binwidth = 0.25, color = "white") +
labs(x = "Residual")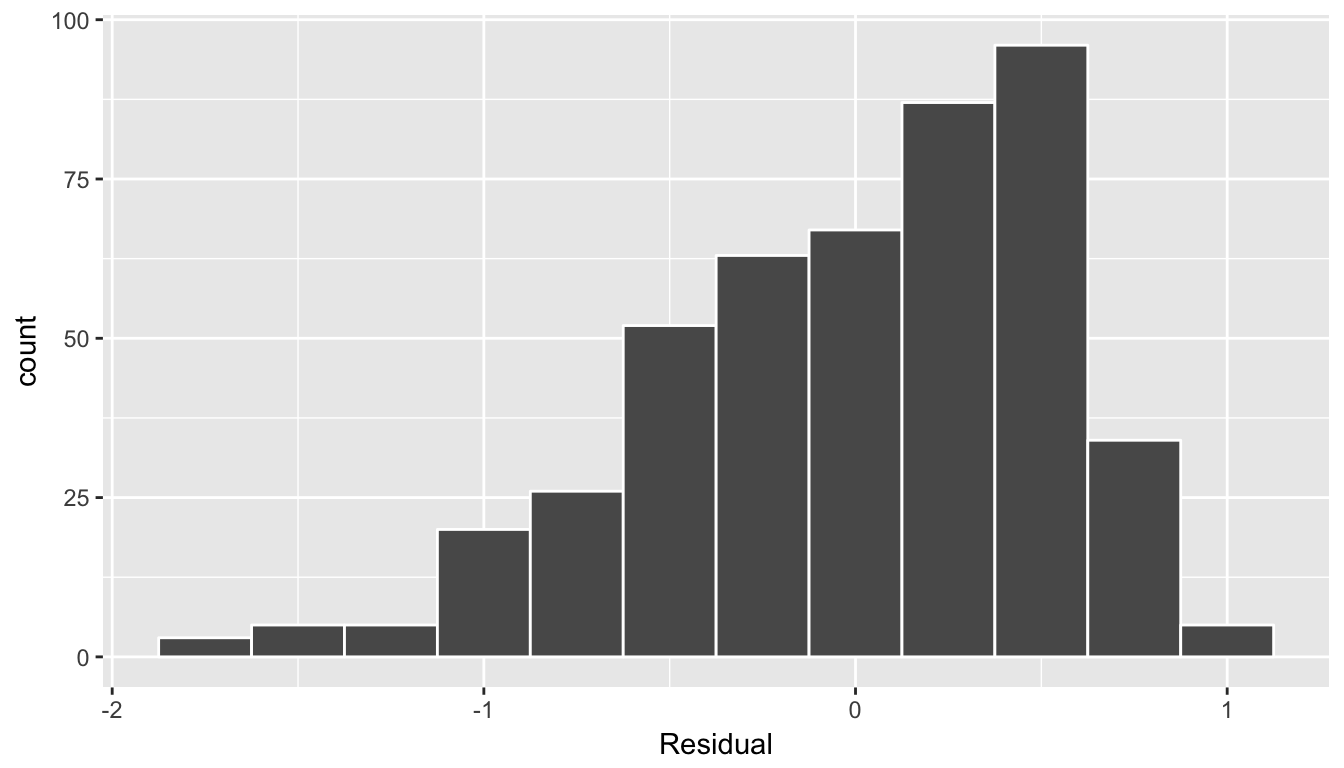
Figure 11.3: Model 2 (with interaction) histogram of residual
Second, the residuals as compared to the predictor variables:
- \(x_1\): numerical explanatory/predictor variable of
age - \(x_2\): categorical explanatory/predictor variable of
gender
ggplot(regression_points, aes(x = age, y = residual)) +
geom_point() +
labs(x = "age", y = "Residual") +
geom_hline(yintercept = 0, col = "blue", size = 1) +
facet_wrap(~ gender)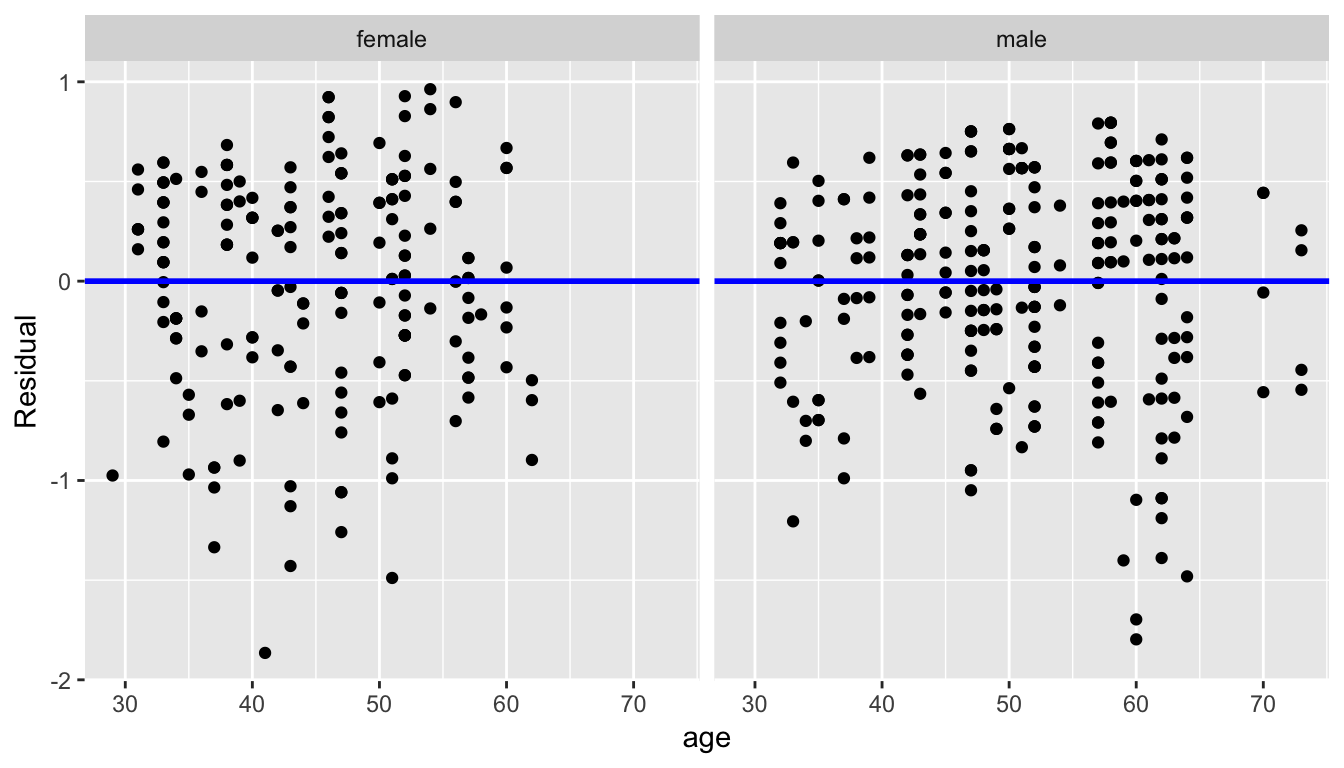
Figure 11.4: Model 2 (with interaction) residuals vs predictor
11.1.4 Script of R code
An R script file of all R code used in this chapter is available here.